Data pipelines, ML infrastructure, and platforms built for real workloads
The software that supports intelligent systems — data warehouses, ML pipelines, internal tools, and API architecture — engineered cleanly, documented thoroughly, and built to be maintained by whoever comes next.
The infrastructure layer intelligent systems depend on
AI systems are only as reliable as the data and infrastructure underneath them. We build both — so the ML layer has what it needs and your team has a system they can maintain.
Data pipelines & warehouses
ML infrastructure & MLOps
Internal platforms & API architecture
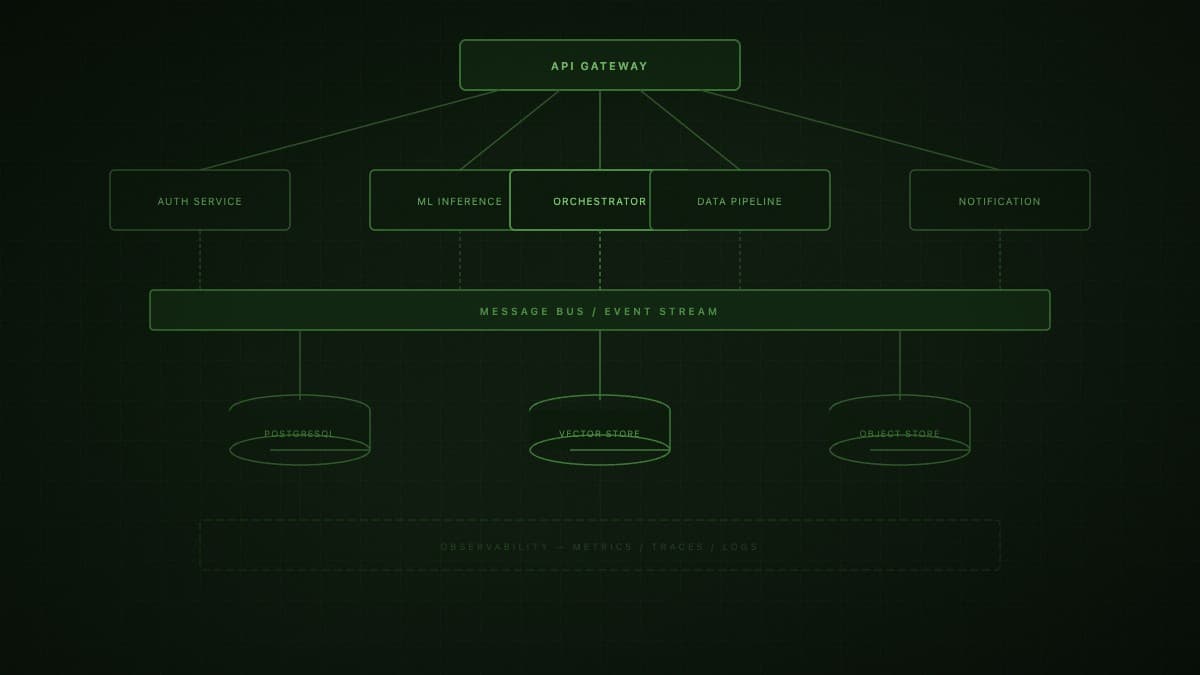
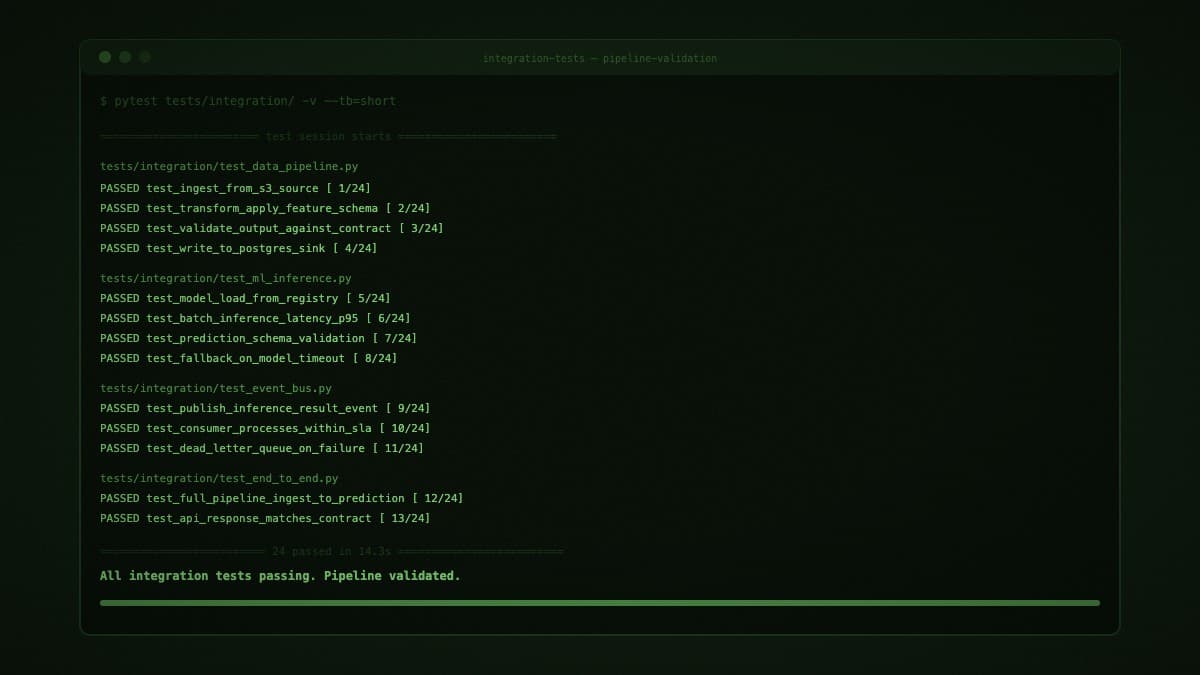
Built like something you are happy to own in two years
Clear contracts, observable systems, and automation where it reduces drag. Software that gets easier to operate over time, not harder — because complexity was resisted, not accumulated.
Documented architecture
Automated CI/CD
Security-first defaults
Observable systems
The systems that last are the ones where the next engineer can understand what was built, why it was built that way, and how to change it safely.
Software measured by what it stops requiring
The best outcome is a system your team stops thinking about — because it runs cleanly, alerts when it should, and changes without drama.
A predictable engineering lifecycle
Enough structure to stay on scope, enough flexibility to respond when requirements clarify. Milestones are agreed upfront and tracked against real deliverables.